A Production-Minded Guide to RAG Evaluation in Rails
You’ve built a RAG system, but how do you ensure it’s not just a clever demo but a reliable, production-grade feature? Answering this requires moving beyond anecdotal checks to a systematic evaluation framework. This guide provides a production-minded approach to building one in Rails, creating a feedback loop to catch regressions and drive improvements.
We’ll build a parallelized Rake task that scores your system on key metrics and integrates with CI/CD, turning evaluation from a chore into an automated part of your development lifecycle.
Why Evaluate? The Feedback Loop is Everything
In traditional software, we have unit tests. In AI, especially with RAG, the system is non-deterministic. A prompt tweak that improves one answer might degrade ten others. Without an automated evaluation loop, you are flying blind. This framework provides:
- Objective Scores: Replace “it feels better” with hard data on faithfulness, relevancy, and correctness.
- Regression Alarms: Automatically detect when a change (in prompts, models, or retrieval logic) hurts performance.
- Data-Driven Improvement: A/B test changes and prove their impact with metrics.
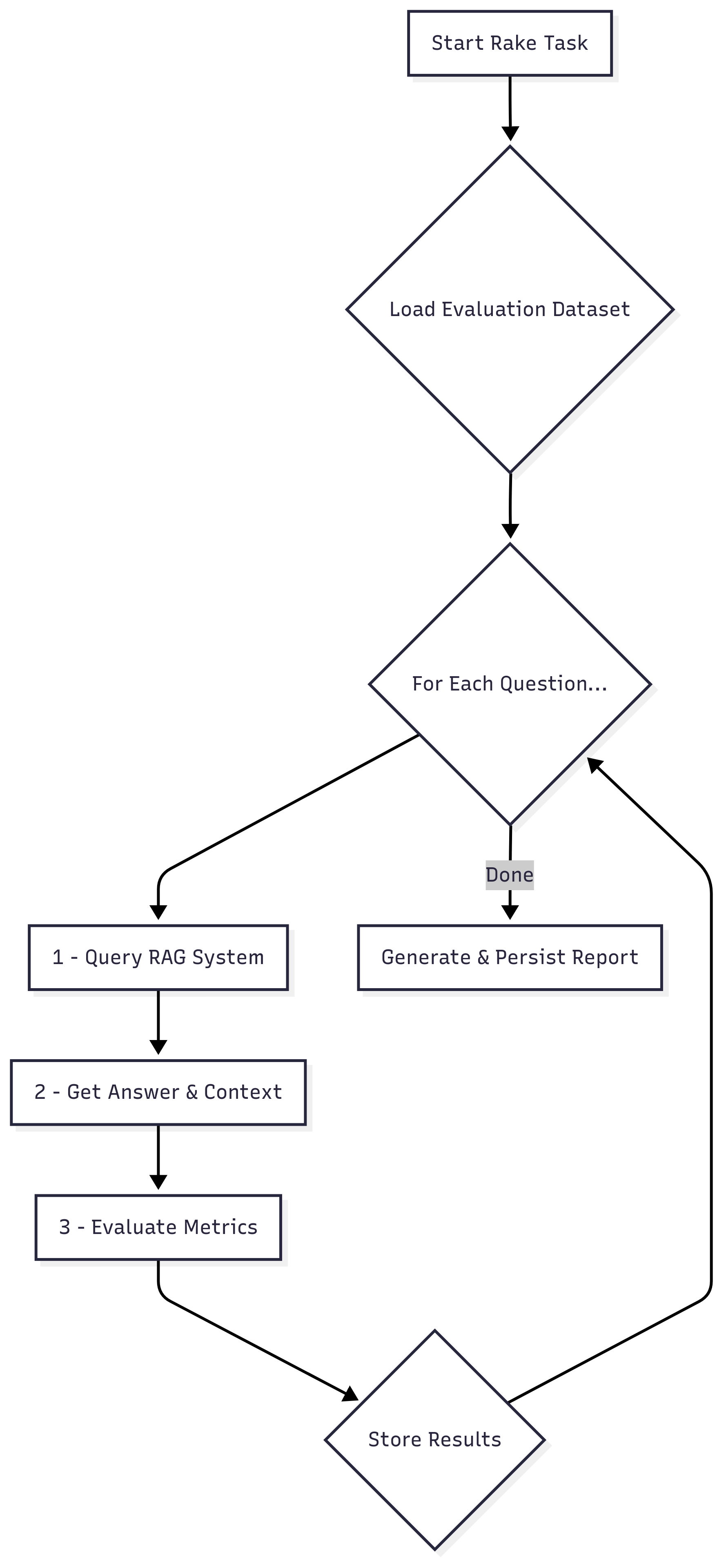
Here’s a flowchart of the system we’ll build:
Prerequisites
This guide assumes you have:
- A
RagQueryServiceand anOpenAiServiceclient (handling keys viaRails.credentials). - An
EmbeddingService. The quality of your correctness score depends heavily on this model (e.g., OpenAI’stext-embedding-3-smallis a good start). - Gems like
parallelandretriablein yourGemfile.
Step 1: A Curated and Versioned Dataset
Your evaluation is only as good as your dataset. Move it from db/ to a more appropriate location like test/fixtures/rag_eval_set_v1.yml.
- Start with 30-50 diverse questions, but plan to grow it. A production system needs hundreds for statistical confidence.
- Ensure Diversity: Include simple lookups, comparisons, summarization tasks, and negative examples (questions your RAG shouldn’t be able to answer).
- Mitigate Bias: Be mindful of biases in your questions. Consider using LLMs to generate variations of your questions to expand the dataset and reduce overfitting.
Step 2: The Evaluator Service
This service is the core of our evaluation, updated for production-level robustness.
app/services/rag_evaluator_service.rb:
# frozen_string_literal: true
class RagEvaluatorService
LLM_TEMPERATURE = 0.0
LLM_TIMEOUT = 30 # seconds
def initialize(question:, generated_answer:, context:, ground_truth:)
# ... (initializer as before)
end
def evaluate
llm_evals = evaluate_with_llm
{
faithfulness: parse_score(llm_evals.dig(:faithfulness, "score")),
answer_relevancy: parse_score(llm_evals.dig(:answer_relevancy, "score")),
answer_correctness: evaluate_correctness_with_embeddings
}
end
private
def evaluate_with_llm
prompt = format(multi_metric_evaluation_prompt, context: @context, question: @question, answer: @generated_answer)
Retriable.retriable(tries: 3, base_interval: 1) do
response = @llm_client.call(prompt: prompt, temperature: LLM_TEMPERATURE, timeout: LLM_TIMEOUT)
return JSON.parse(response)
end
rescue StandardError => e # Catch persistent errors after retries
Rails.logger.error "RAG-Eval: LLM call failed after retries: #{e.message}"
{}
end
def evaluate_correctness_with_embeddings
# ... (as before)
end
def cosine_similarity(vec_a, vec_b)
# Manual implementation removes dependency on non-existent gems.
dot_product = vec_a.zip(vec_b).sum { |a, b| a * b }
mag_a = Math.sqrt(vec_a.sum { |x| x**2 })
mag_b = Math.sqrt(vec_b.sum { |x| x**2 })
return 0.0 if mag_a.zero? || mag_b.zero?
dot_product / (mag_a * mag_b)
rescue StandardError => e
Rails.logger.error "RAG-Eval: Cosine similarity failed: #{e.message}"
0.0
end
def parse_score(score)
# ... (as before)
end
def multi_metric_evaluation_prompt
<<~PROMPT
You are an expert evaluator. Your task is to assess a generated answer based on a provided context and question.
Provide your assessment for each of the following metrics.
**Context:**
%{context}
**Question:**
%{question}
**Generated Answer:**
%{answer}
Respond ONLY with a single JSON object with two top-level keys: "faithfulness" and "answer_relevancy".
Each key should contain a JSON object with a "score" (float from 0.0 to 1.0) and "reasoning" (string).
- **Faithfulness**: Is every claim in the generated answer supported by the context?
- **Answer Relevancy**: Does the answer directly and completely address the user's question?
PROMPT
end
end
Step 3: The Rake Task
This version correctly handles failures, calculates all metrics, and persists results with headers.
lib/tasks/rag.rake:
require 'yaml'
require 'table_print'
require 'parallel'
require 'csv'
namespace :rag do
desc "Evaluates the RAG system against a predefined dataset"
task evaluate: :environment do
EVAL_THREADS = ENV.fetch('RAG_EVAL_THREADS', 4).to_i
FAITHFULNESS_THRESHOLD = ENV.fetch('RAG_FAITH_THRESHOLD', 0.75).to_f
RESULTS_CSV_PATH = Rails.root.join('log', 'rag_evaluation_history.csv')
puts "Starting RAG evaluation..."
dataset = YAML.load_file(Rails.root.join('test', 'fixtures', 'rag_eval_set_v1.yml'))
all_results = Parallel.map(dataset, in_threads: EVAL_THREADS) do |item|
# ... (logic to call service, returning error hash on failure)
end
successes = all_results.reject { |r| r[:error] }
failures = all_results.select { |r| r[:error] }
# ... (reporting for successes and failures)
return puts "\nNo successful results to analyze." if successes.empty?
avg_scores = {
faithfulness: (successes.sum { |r| r[:faithfulness] } / successes.size).round(3),
relevancy: (successes.sum { |r| r[:answer_relevancy] } / successes.size).round(3),
correctness: (successes.sum { |r| r[:answer_correctness] } / successes.size).round(3)
}
# ... (print average scores)
# Persist results with headers
headers = ['timestamp', 'avg_faithfulness', 'avg_relevancy', 'avg_correctness', 'success_rate']
CSV.open(RESULTS_CSV_PATH, 'a') do |csv|
csv << headers if csv.count.zero?
csv << [Time.now.iso8601, avg_scores[:faithfulness], avg_scores[:relevancy], avg_scores[:correctness], (successes.size.to_f / all_results.size).round(3)]
end
if avg_scores[:faithfulness] < FAITHFULNESS_THRESHOLD
raise "Faithfulness score #{avg_scores[:faithfulness]} is below the #{FAITHFULNESS_THRESHOLD} threshold!"
end
end
end
Step 4: Production Considerations
- Cost & Rate Limiting: LLM calls are not free. A 100-question dataset run on every commit can get expensive. Consider running evaluations on a schedule or manually, and be aware of your API provider’s rate limits.
- Scaling Evaluations: For very large datasets, consider a more robust solution than a Rake task. You could trigger background jobs (e.g., Sidekiq) for each evaluation item and use a separate process to aggregate the results.
- Monitoring: The persisted CSV is a good start. In production, feed this data into a monitoring tool like Datadog or Grafana to create dashboards and set up alerts for significant performance drops.
Step 5: CI/CD with PR Comments
This workflow triggers on relevant file changes and posts a summary back to the PR.
.github/workflows/rag_evaluation.yml:
name: RAG Evaluation
on:
pull_request:
paths:
- "app/services/rag_evaluator_service.rb"
- "lib/tasks/rag.rake"
- "test/fixtures/rag_eval_set_*.yml"
jobs:
evaluate:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: ruby/setup-ruby@v1
with: { "ruby-version-file": ".ruby-version", bundler-cache: true }
- name: Run RAG Evaluation
# ... (as before)
- name: Comment on PR with Results
# ... (as before, with if: always())
This guide provides a resilient and production-minded framework for RAG evaluation. By handling failures, persisting results for trend analysis, and integrating with CI/CD, you create a powerful feedback loop to ensure your AI features are not just clever, but consistently reliable.